大規模言語モデル / AI エージェント 受託研究開発サービス
高い専門性が必要とされる業務において AI エージェント構築と運用を支援します。大規模言語モデルを活用した実用的なアプリケーションから純粋な研究目的まで、広範なニーズに対応いたします。最新の AI エージェントや大規模言語モデルの調査・コンサルティングもお任せください。仕様がはっきりと決まっていない初期段階でのご相談も承ります。お気軽にお問い合わせください。
AI エージェント性能改善支援
キーワード: RAG, Agentic RAG, LangGraph, Codex SDK, Context Engineering
- 多様な形式の蓄積ノウハウを活用した AI エージェントの開発
- 社内技術レポートや過去の対応履歴にもとづいて質問応答精度を改善
- AI により AI の性能を自動定量評価するシステムの開発
- AI エージェントの性能を多観点で継続的に自動評価するシステムの構築
- インターフェース開発やクラウド環境へのデプロイ
- 外部システム連携、認証等の機能の開発

研究開発業務向け AI エージェント拡張
キーワード: AI Agent, MCP, OpenAI Agents SDK, A2A, AGENTS.md, Skills
- 研究開発業務を効率化する AI エージェントの開発
- 自動論文調査や公開 DB の探索が可能な研究開発業務に特化した AI を構築
- コーディング AI 並列利用を前提とする開発体制の運用支援
- 貴社開発環境でコーディング AI を並列運用する際のノウハウを提供
- AI エージェントと既存アプリケーションの連携
- 貴社アプリケーションを AI エージェントから利用可能にする API の開発

機密データ対応の生成 AI システム開発
キーワード: ローカル LLM, SLM, Evals, Safeguard, vLLM, SGLang, 匿名化
- オンプレ環境で動作するローカル LLM の実装とチューニング
- 多人数で使用されるローカル LLM の推論速度の最適化
- オンプレ環境で動作するリアルタイム議事録生成システムの開発
- ローカル動作の音声認識モデルを使い会議音声から議事録を生成
- 非構造化データの匿名化による外部共有可能な学習データ生成
- 非構造データ中の人名、地名、住所などを匿名化し、個人情報を保護

大規模言語モデルに関する研究開発
キーワード: GRPO, DPO, SFT, Mamba, SSM, MoE, DSPy, GEPA
- 最新論文の追試と拡張
- 訓練データ収集用の大規模 ETL 開発
- 大規模言語モデルを用いた文字列を入力とする回帰モデル実装
- AI 向けプロンプトの自動生成および自動チューニング

開発実績例
進化的計算と LLM による数理アルゴリズムの自動改良
大規模言語モデルと進化的計算を組み合わせ、数理アルゴリズムを自律的に改良するシステムを構築しました。CLI 型 AI コーディング エージェントがアルゴリズムの修正・評価を繰り返し実行します。
48 時間の自動実行により、人手によるチューニングを上回る性能(Accuracy: 0.914 → 0.956)を達成しました。
<開発環境・技術分野: Automated Algorithm Design, CLI 型 AI コーディング エージェント, 進化的計算>
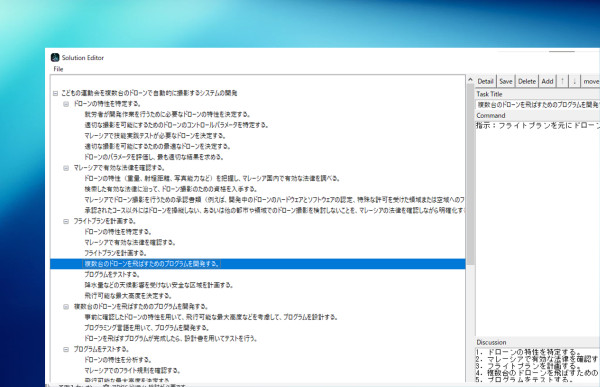
LLM を反復的に利用した自動計画システム
大規模言語モデルの出力を反復的に詳細化することで、ソフトウェア開発分野の自動計画を行うシステムを構築しました。
本システムは、ソフトウェアの要求仕様を入力として与えると、GUI 上で対話的に要求の詳細を確認しながら、目標達成に必要なタスクへの分解を行います。実際に弊社での業務に使用しています。
<開発環境・技術分野: 大規模言語モデル, AI エージェント>